就数据库的使用给出 CURD、JOIN 和 EXPLAIN 的示例
写在前面
对一般的开发者来说,MySQL 安装成功以后,剩下的就是基本的使用了,如果是运维开发,可能还会涉及到数据库的运维。本文暂且不考虑运维上的操作,仅就数据库的使用给出一些示例,主要包括 CURD、JOIN 和 EXPLAIN。
适用人群
入门——初级——中级√——高级;本文适应中级及以上。
数据库的基本使用
数据库的安装与启动
目前常见的操作系统有三类:Linux、Windows、Mac。不同平台安装软件的方式各异,安装过程中可能遇到的问题也各不相同,大家可以根据自己所使用的平台进行探索。因为本人使用的是 Mac,因此只给出 Mac 操作系统上 MySQL 的安装与启动。
简单总结下来就是下面几个命令
# 安装 homebrew, 参考 https://brew.sh/
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
# 查找可以安装的 mysql 方案
brew search mysql
# 安装 5.7 版本的 mysql
brew install mysql@5.7
# 查看 mysql@5.7 的安装信息、启动信息等
brew info mysql@5.7
# 开机启动 mysql@5.7
brew services start mysql@5.7
连接数据库服务
启动 MySQL 后,我们可以通过 ps -ef |grep mysql 来查看与 MySQL 相关的进程,可以发现 后台会运行一个 mysqld 的进程,也就是说我们通常所说的 “连接数据库” 其实指的是连接 mysqld 提供的数据库服务。
一般本地(自己的电脑上面)安装完 MySQL 后,会默认安装 mysql 这个命令,可以用它来连接 mysqld 提供的服务(因为真正提供数据库服务的是 mysqld,或许 MySQL 应该叫 MySQLD 比较好? 😆)。
# 连接本地 localhost 端口为 3306 的数据库 hello
# 使用 root 用户,且要求输入密码
mysql -h localhost -P 3306 -D hello -u root -p
# 我们可以忽略 -h 和 -P 来简化上面的语句
# 下面的语句表示: 以 root 用户连接本地 3306 端口上的数据库 hello
mysql -D hello -u root -p
# 如果不需要指定连接哪个数据库,还可以省略 -D 及其参数
mysql -u root -p
# 如果需要指定字符集为 utf8mb4,需要添加(如果要存储 emoji 就必须要指定这个字符集)
mysql -u root -p --default-character-set=utf8mb4
创建数据库
连接到数据库以后,我们可以通过下面的语句创建一个数据库。
-- SQL 的注释使用的是 双横线 “--”
-- 如果 hello 数据库已经存在,就显式地先删除这个数据库
-- 然后创建一个名为 hello 的数据库,并指定其默认的字符集为 utf8mb4
-- 大家可以自行搜索 MySQL utf8mb4 相关的内容
DROP DATABASE IF EXISTS hello;
CREATE DATABASE `hello` DEFAULT CHARACTER SET = `utf8mb4`;
-- 有了数据库以后就可以使用这个数据库了,然后才可以在数据库中创建表
USE hello;
创建数据表
接下来我们模仿一个博客系统创建几个数据表,分别包括用户表 users、博客表 blogs 和评论表 comments。
在创建表的时候我们有几个默认项,数据库引擎使用 InnoDB(小白用户只需要记住 InnoDB 可以满足绝大部分场景),字符集使用 utf8mb4。由于 InnodB 的 “聚簇索引” 和“二级索引包含引用行的主键列”的特性,默认情况下我们会创建一个类型为 int 的主键 id。
创建 users 表
下面的语句创建了用户 users 表。
-- 为了试验环境的干净整洁,首先检查是否已经存在 users 表
-- 如果已经存在 users 表就先删除掉,接着创建 users 表
-- 用户表中包含的字段及其含义可以查看 COMMENT 中备注的内容
DROP TABLE if EXISTS users;
CREATE TABLE `users` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键,用户 id',
`created_at` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`username` varchar(100) DEFAULT NULL COMMENT '用户名',
`birthday` datetime DEFAULT NULL COMMENT '生日日期',
PRIMARY KEY (`id`),
KEY `idx_user_created_at` (`created_at`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4;
创建 blogs 表
下面的语句创建了博客 blogs 表。
-- 为了试验环境的干净整洁,首先检查是否已经存在 blogs 表
-- 如果已经存在 blogs 表就先删除掉,接着创建 blogs 表
-- 用户表中包含的字段及其含义可以查看 COMMENT 中备注的内容
DROP TABLE if EXISTS blogs;
CREATE TABLE `blogs` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键,博客 id',
`created_at` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`user_id` int(11) DEFAULT NULL COMMENT '用户id',
`title` varchar(50) DEFAULT NULL COMMENT '博客标题,最多 50 个字符',
`content` text DEFAULT NULL COMMENT '博客内容',
PRIMARY KEY (`id`),
KEY `idx_blogs_created_at` (`created_at`) USING BTREE,
KEY `idx_blogs_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4;
创建 comments 表
下面的语句创建了评论 comments 表。
-- 为了试验环境的干净整洁,首先检查是否已经存在 comments 表
-- 如果已经存在 comments 表就先删除掉,接着创建 comments 表
-- 用户表中包含的字段及其含义可以查看 COMMENT 中备注的内容
DROP TABLE if EXISTS comments;
CREATE TABLE `comments` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键,评论 id',
`created_at` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`user_id` int(11) DEFAULT NULL COMMENT '用户 id',
`blog_id` int(11) DEFAULT NULL COMMENT '博客 id',
`content` varchar(2048) DEFAULT NULL COMMENT '评论内容,限制最多 2048 个字符',
PRIMARY KEY (`id`),
KEY `idx_blogs_created_at` (`created_at`) USING BTREE,
KEY `idx_blogs_user_id` (`user_id`) USING BTREE,
KEY `idx_blogs_blog_id` (`blog_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4;
创建一些假数据便于后面检索使用
-- 首先下面手动给每个表插入了一条记录
INSERT INTO `users` (`id`, `username`, `birthday`) VALUES (NULL, 'ws_by_hand_1', NULL);
INSERT INTO `blogs` (`id`, `user_id`, `title`, `content`) VALUES (NULL, '1', '海燕', '高尔基的作品。');
INSERT INTO `blogs` (`id`, `user_id`, `title`, `content`) VALUES (NULL, '1', '我的大学', '高尔基的另一部作品。');
INSERT INTO `comments` (`id`, `user_id`, `blog_id`, `content`) VALUES (NULL, '1', '1', '我也喜欢高尔基的作品😆');
INSERT INTO `comments` (`id`, `user_id`, `blog_id`, `content`) VALUES (NULL, '1', '2', '这一部我也很喜欢😆');
-- 为了说明问题,下面定义了一个创建多个虚拟用户的过程
DELIMITER ;;
DROP PROCEDURE if EXISTS mock_users;
CREATE PROCEDURE mock_users()
BEGIN
DECLARE i INT;
SET i = 1;
WHILE i < 1000 DO
INSERT INTO `users` (`id`, `username`, `birthday`) VALUES (NULL, CONCAT("ws_auto_",i), NULL);
INSERT INTO `blogs` (`id`, `user_id`, `title`, `content`) VALUES (NULL, i, '背影', '朱自清的作品。');
INSERT INTO `comments` (`id`, `user_id`, `blog_id`, `content`) VALUES (NULL, i+1, i, '我也喜欢😆');
SET i = i + 1;
END WHILE;
END ;;
DELIMITER ;
-- 调用 mock_users 生成多个用户账户,以及对应的 blogs 和 comments
CALL mock_users()
JOIN 的使用
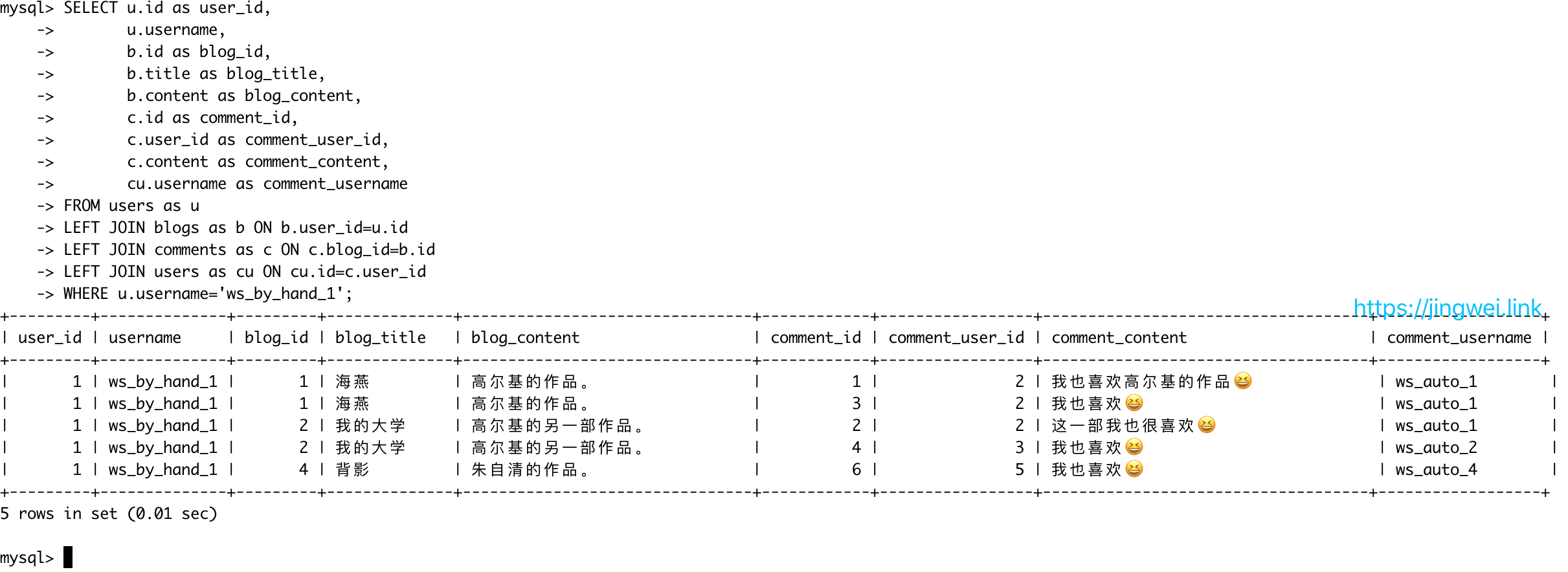
我们可以通过 JOIN 的方式来获取某个用户发表的博客的所有内容,以及其博客所获得的评论内容。
SELECT u.id as user_id,
u.username,
b.id as blog_id,
b.title as blog_title,
b.content as blog_content,
c.id as comment_id,
c.user_id as comment_user_id,
c.content as comment_content,
cu.username as comment_username
FROM users as u
LEFT JOIN blogs as b ON b.user_id=u.id
LEFT JOIN comments as c ON c.blog_id=b.id
LEFT JOIN users as cu ON cu.id=c.user_id
WHERE u.username='ws_by_hand_1';
获取到的结果如下图所示(可以通过指定字段来选择性的检出对应的字段的内容):
EXPLAIN 的使用
因为我们的表的内容比较少,因此运行上面 JOIN 的内容不会有慢的感觉,但是我们依然可以使用 EXPLAIN 进行一番探索。
EXPLAIN
SELECT u.id as user_id,
u.username,
b.id as blog_id,
b.title as blog_title,
b.content as blog_content,
c.id as comment_id,
c.user_id as comment_user_id,
c.content as comment_content,
cu.username as comment_username
FROM users as u
LEFT JOIN blogs as b ON b.user_id=u.id
LEFT JOIN comments as c ON c.blog_id=b.id
LEFT JOIN users as cu ON cu.id=c.user_id
WHERE u.username='ws_by_hand_1';
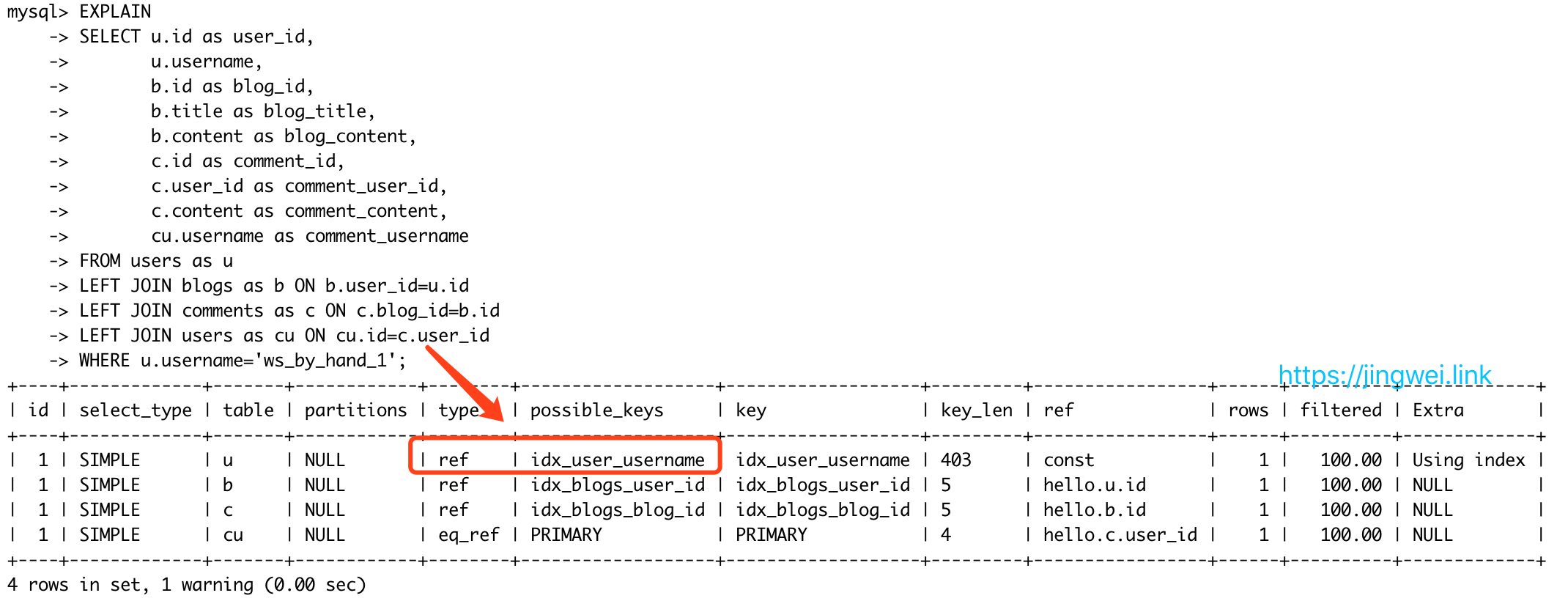
上面的 EXPALIN 代码运行后得到的结果如下图所示。我们可以通过查看 type 一列探索索引的使用情况,发现 users as u 表扫了全量表(type 为 ALL),当我们的 user 表非常大的情况下,这里肯定会存在问题。其实在创建 users 表的时候我刻意少创建了一个索引,理论上应该在 users.username 这个字段上添加索引。

在 users.username 字段上添加索引
可以通过下面的语句为 users.username 字段添加索引:
ALTER TABLE `users` ADD INDEX `idx_user_username` (`username`);
在添加完索引以后,在此 EXPLAIN 我们的 JOIN 语句,可以得到下图的结果。可以发现 users as u的 type 已经变成了字段 username (idx_user_username)上的索引ref。
小结
本文就数据库的使用给出一些示例,通过实例代码的方式给出 CURD、JOIN 和 EXPLAIN的使用方式,在实际生产过程中可以为大家提供一些参考。
对于 ORM 工具的使用,在检索的过程中本质是 SQL 语句的拼装、检索结果的解析,在数据库层面了解 SQL 无疑能够增强大家对 ORM 的使用的理解,从而写出更加高效可靠的代码。
参考
- The missing package manager for macOS (or Linux) — Homebrew macOS 上强大的包管理器
- MySQL Explain详解 - 博客园 比较详尽的介绍 explain 的内容
- 卸载 macOS 中的 MySQL 时遇到的疑问 - 敬维 在 macOS 上安装/卸载 mysql 的介绍
