简单介绍协程(goroutine) 的调度以及抢占
写在前面
过去 Web 开发的工作比较少涉及到并发的问题,每个用户请求在独立的线程里面进行,偶尔涉及到异步任务但是线程间数据同步模型非常简单,因此并未深入探究过并发这一块。最近在写游戏相关的服务端代码时发现数据的并发同步场景非常多,因此花了一点时间来探索和总结。这是一个系列文章,本文为第五篇。
就像前面几篇文章所描述的,开发者在日常开发中对并发的关注点主要是锁、管道(channel),比较少涉及到协程(goroutine) 的调度。不过了解协程的调度机制能够让开发者更好地认识并发的本质,从而在日常编码过程中做出更好的并发保证措施。本文简单介绍 Golang 中协程(goroutine)的调度及其抢占。
先看两段代码
第一段代码
下面的代码是《浅谈 Golang 中数据的并发同步问题(二)》中的一个示例 demo,为了说明问题增加了对单核的限制。运行 go run -race main.go 可以看到 Money: 1100 的输出。
下面的代码中包含两条 atomic.AddInt64 语句,分别在两个协程中运行。如果在 fmt.Printf 语句执行时子协程已经执行,输出结果是 Money: 2100;当然,上面的代码极大概率会输出 Money: 1100 ,即在 fmt.Printf 语句执行时子协程尚未执行。那么, Golang 调度器何时才会调度并运行子协程呢?
// cat main.go
package main
import (
"fmt"
"runtime"
"sync/atomic"
)
type Person struct {
Money int64
}
func main() {
runtime.GOMAXPROCS(1)
p := Person{Money: 100}
go func() {
atomic.AddInt64(&p.Money, 1000)
}()
atomic.AddInt64(&p.Money, 1000)
fmt.Printf("Money: %d\n", atomic.LoadInt64(&p.Money))
}
第二段代码
我们可以构造一段与上一小节结构类似的代码,如下面的代码所示。通过 go run main.go 运行下面的代码可以看到输出结果中的 panic: hello goroutine ,却找不到sum: xxxxxx(如果看到的结果不一致,可以考虑增加 for 循环的终止判定条件)。也就是说,下面的代码的子协程在代码退出前被成功调度。
// cat main.go
package main
import (
"fmt"
"runtime"
"time"
)
func printTime(n int) {
now := time.Now()
fmt.Printf("Index: %d, Second: %d, NanoSecond: %d \n", n, now.Second(), now.Nanosecond())
}
func main() {
runtime.GOMAXPROCS(1)
go func() {
printTime(2)
panic("hello goroutine")
}()
printTime(1)
sum := 0
for i := 0; i < 666666666; i++ {
sum += i
}
fmt.Printf("sum: %d\n", sum)
}
协程 goroutine 的抢占
在 Golang 中可以非常方便地创建协程(goroutine),在可用核心一定的条件下,协程该如何有效地利用 CPU 资源呢?在《Linux系统调度原理浅析(二)》中简单描述过 Linux 内核的调度机制以及 goroutine 的调度机制:其中 Linux 内核通过时间片的方式给不同的系统线程分配 CPU 资源,Golang 则引入了 G/P/M 模型来实现调度,那么 Golang 的运行时(runtime)如何实现对 goroutine 的调度从而合理分配 CPU 资源呢?
G/P/M 模型
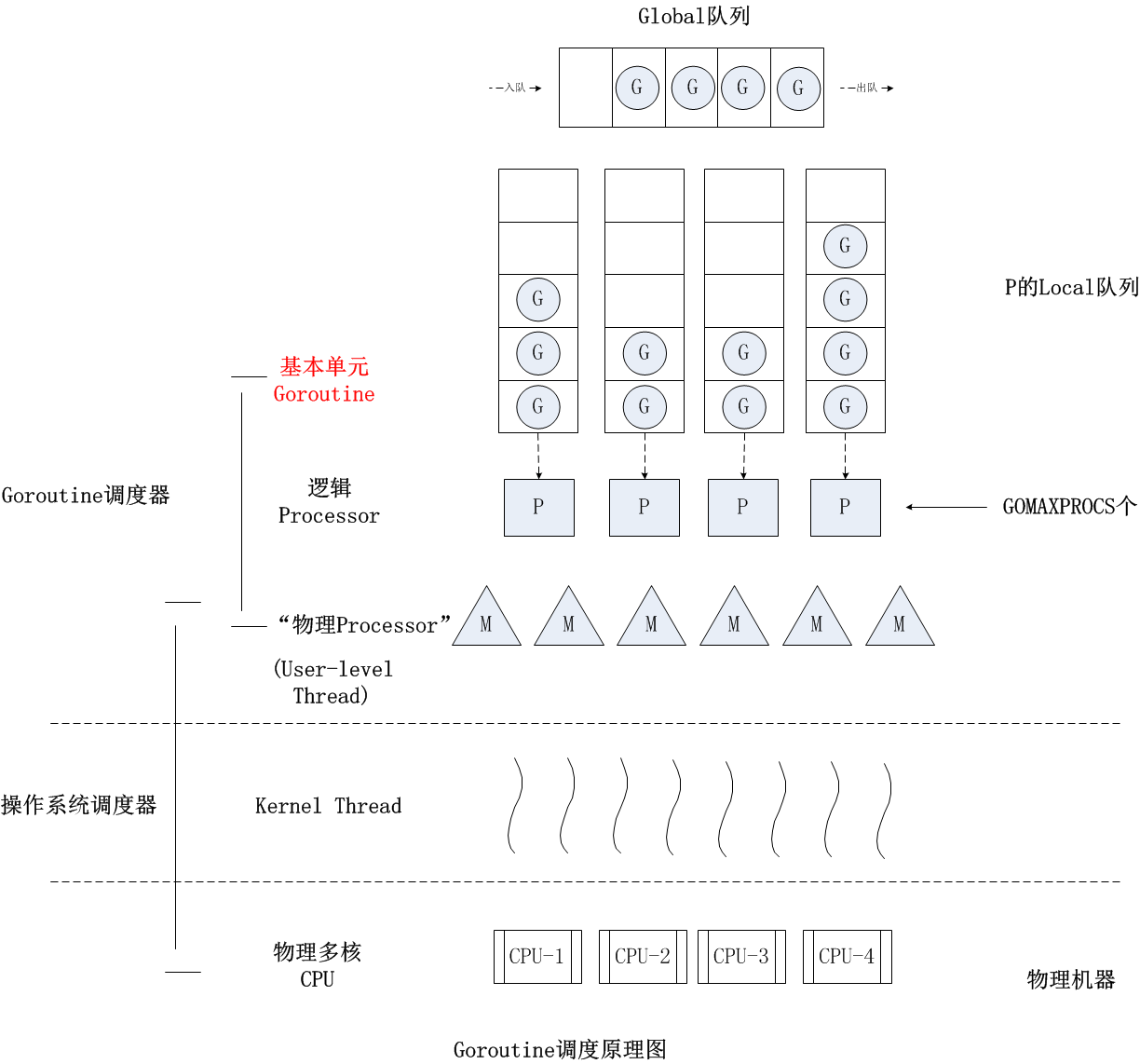
(图片摘自《也谈goroutine调度器 - Tony Bai》)
P 是一个“逻辑 Proccessor”,每个 G 要想真正运行起来,首先需要被分配一个 P(进入到 P 的 local runq 中,这里暂忽略 global runq 那个环节)。对于 G 来说,P 就是运行它的 “CPU”,可以说:G 的眼里只有 P。但从 Go scheduler 视角来看,真正的 “CPU” 是 M,只有将 P 和 M 绑定才能让 P 的 runq 中 G 得以真实运行起来。这样的 P 与 M 的关系,就好比 Linux 操作系统调度层面用户线程 (user thread) 与核心线程 (kernel thread) 的对应关系那样,都是 (n × m) 模型。具体地:
- G: 表示 goroutine,存储了 goroutine 的执行 stack 信息、goroutine 状态以及 goroutine 的任务函数等;另外 G 对象是可以重用的。
- P: 表示逻辑 processor,P的数量决定了系统内最大可并行的 G 的数量(前提是系统的物理 CPU 核数>=P 的数量,可以
runtime.GOMAXPROCS(20)增加 P 数量大于 CPU 核数);P 的最大作用还是其拥有的各种 G 对象队列、链表、一些 cache 和状态。 - M: M代表着真正的执行计算资源。在绑定有效的 P 后,进入 schedule 循环;而 schedule 循环的机制大致是从各种队列、P 的本地队列中获取 G,切换到 G 的执行栈上并执行G的函数,调用 goexit 做清理工作并回到 M,如此反复。M并不保留 G 状态,这是 G 可以跨 M 调度的基础。
goroutine 发生调度的时机
假如忽略(G、P、M)模型的复杂性,可以想象一个 goroutine 获得计算资源(CPU)后一般不能一直运行到完毕,它们往往可能要等待其他资源才能执行完成,比如读取磁盘文件内容、通过 RPC 调用远程服务等,在等待的过程中 goroutine 是不需要消耗计算资源的,因此调度器可以把计算资源给其他的 goroutine 使用。
参考《Golang goroutine》可以知道,goroutine 遇到下面的情况下可能会产生重新调度(大家判断哪些代码属于下面这些情况):
- 阻塞 I/O
- select操作
- 阻塞在channel
- 等待锁
- 主动调用 runtime.Gosched()
goroutine 的抢占
如果一个 goroutine 不包含上面提到的几种情况,那么其他的 goroutine 就无法被调度到相应的 CPU 上面运行,这是不应该发生的。这时候就需要抢占机制来打断长时间占用 CPU 资源的 goroutine ,发起重新调度。
Golang 运行时(runtime)中的系统监控线程 sysmon 可以找出“长时间占用”的 goroutine,从而“提醒”相应的 goroutine 该中断了。
特别说明-1:sysmon在独立的 M(线程)中运行,且不需要绑定 P。这意味着,runtime.GOMAXPROCS(1)限制 P 的数量为 1 的情况下,即使一个 goroutine 一直占用这个 P 进行密集型计算(意味着 goroutine 一直占有唯一的 P),依然不影响 sysmon 的正常运行。
特别说明-2:sysmon 可以找到“长时间占用 P”的 goroutine,但也只是标记 goroutine 应该被抢占了,并无法强制进行 goroutine 的切换。因此本文的 “第二段代码” 在进行 for 循环时并不会被抢占,而是在 for 循环结束后执行 fmt.Printf("sum: %d\n", sum) 的时候才被抢占(因为 for 循环里没有被插入抢占检查点,也就是说抢占检查点是编译器预先插入的,在非内联的函数的前面,具体可以查看最后几篇参考文章)。
小结
本文从两段代码切入,探究了 goroutine 的调度以及抢占。对于本文的第一段代码,主协程的代码并不需要消耗 forcePreemptNS(默认为 10 ms)时长的资源,而主线程也没有主动把资源让出来,因此子协程没有运行。对于本文的第二段代码,由于 for 循环消耗了大量的计算资源,满足了 forcePreemptNS 时间阈值,调用 fmt.Printf 时触发了抢占,因此子协程得以运行。
本文的编写历时好几天,期间查阅了大量的资料,修修改改好几次,导致本文的架构比较松散;如果大家对本文有什么疑问,可以直接邮件我进行交流 🤝。
参考
- skoo goroutine与调度器 比较经典的比喻,描述了调度的机制
- Golang goroutine - 简书 介绍了抢占式调度的机制
- 也谈goroutine调度器 - Tony Bai 比较系统地介绍了 goroutine 的调度
- Linux系统调度原理浅析(二) - 敬维 简单介绍了 linux 系统调度
- go/proc.go at release-branch.go1.12 · golang/go · GitHub
forcePreemptNS强制协程调度的变量,默认为10 ms。 - go/proc.go at release-branch.go1.12 · golang/go · GitHub 如果一个 goroutine 长时间占用计算资源,
sysmon可以触发抢占;sysmon在独立的 M(线程)中运行,且不需要绑定 P。 - go/stack.go at release-branch.go1.12 · golang/go · GitHub Golang 编译器会在每个非内联函数前面运行栈溢出检查,如果栈溢出则扩展栈,从而执行
newstack()函数,继而触发抢占机制 - Debugging performance issues in Go programs - Intel® Software
- runtime: tight loops should be preemptible · Issue #10958 · golang/go · GitHub 介绍了空 for 的不可中断
- Scheduling In Go : Part II - Go Scheduler if you run any tight loops that are not making function calls, you will cause latencies within the scheduler and garbage collection
- goroutine - Why is this Go code blocking? - Stack Overflow 介绍了为什么 for{} 无限
