为优化日志收集方案做参考
写在前面
部署到 K8s 后,应用将以 Pod 的形式运行在 K8s 集群任意的通用 Worker 节点上面,因此应用运行过程中打印的日志也分散在这些节点上,那么如何才能把这些分散在各处的日志收集起来继而查看分析呢?其实 K8s 官方有专门的文档描述 日志收集的方案 ,且文档中几乎涵盖了所有的日志收集场景。日志收集的方案很容易理解,那么日志收集还有什么难的呢?难的是日志收集的工程实现!
本文将对日志收集过程中会用到的一些知识点(文件系统、Ext4、磁盘寻址、SSD/HDD 等)进行探究,并尝试讨论各个组件的理论极限值,从而为优化日志收集方案做参考。
适用人群
入门——初级——中级√——高级;本文适应中级及以上。
如何让日志收集得又快又稳
先看两种日志收集架构
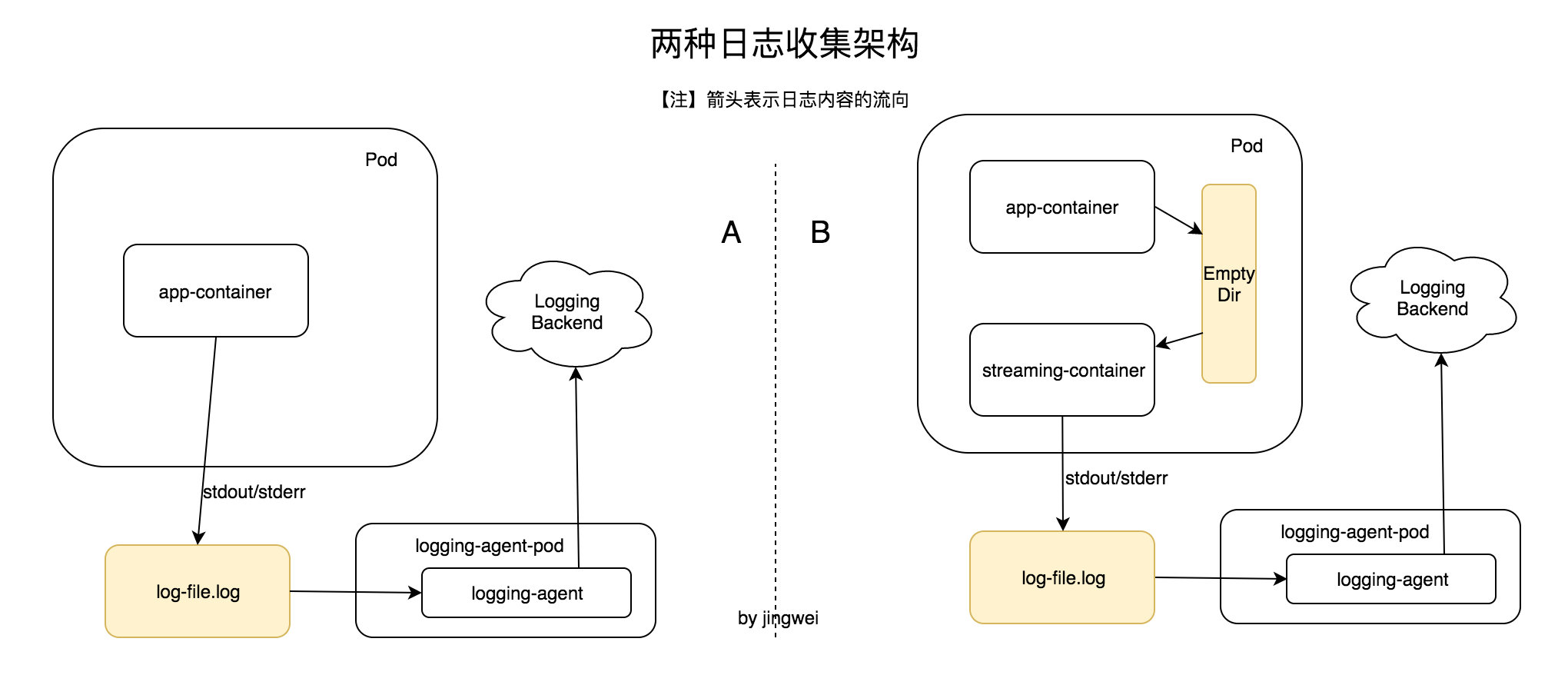
假设有上图中的两种方案,基本是官方文档中 A)普通代理模式 和 B)边车+代理模式 这两个模型的微变体,从图中可以看到两种方案均存在 logging-agent 组件,用来异步地把日志推送到远端(Logging Backend,比如 Logstash 或者 Kafka 等)。方案 A 与 方案 B 的最大区别是:前者没有 Empty Dir(后面简称 ED),日志直接写到了 log-file.log;而后者有 ED,日志首先写入 ED,然后经由另一个容器(streaming-container)把日志转发到 log-file.log(方案 B 适用于那些没有办法把日志写入 stdout/stderr 的应用)。
有了方案架构图,接下来就方便讨论了(架构的意义,见《从 Clean-Architecture 谈架构原理及其应用 》)。
文件系统
对于前面提到的方案 A (应用直写 log-file.log),其本质上是直写本地磁盘,因此无需考虑性能优化问题(如果写本地磁盘有性能瓶颈,直接查代码逻辑吧,最差情况是考虑换磁盘)。对于方案 B,虽说本质上它也是直写本地磁盘,但是存在两次落盘的过程(两次写操作一次读操作),这种情况会不会出现性能问题呢?这就需要了解一下 Linux 文件系统的工作机制了。
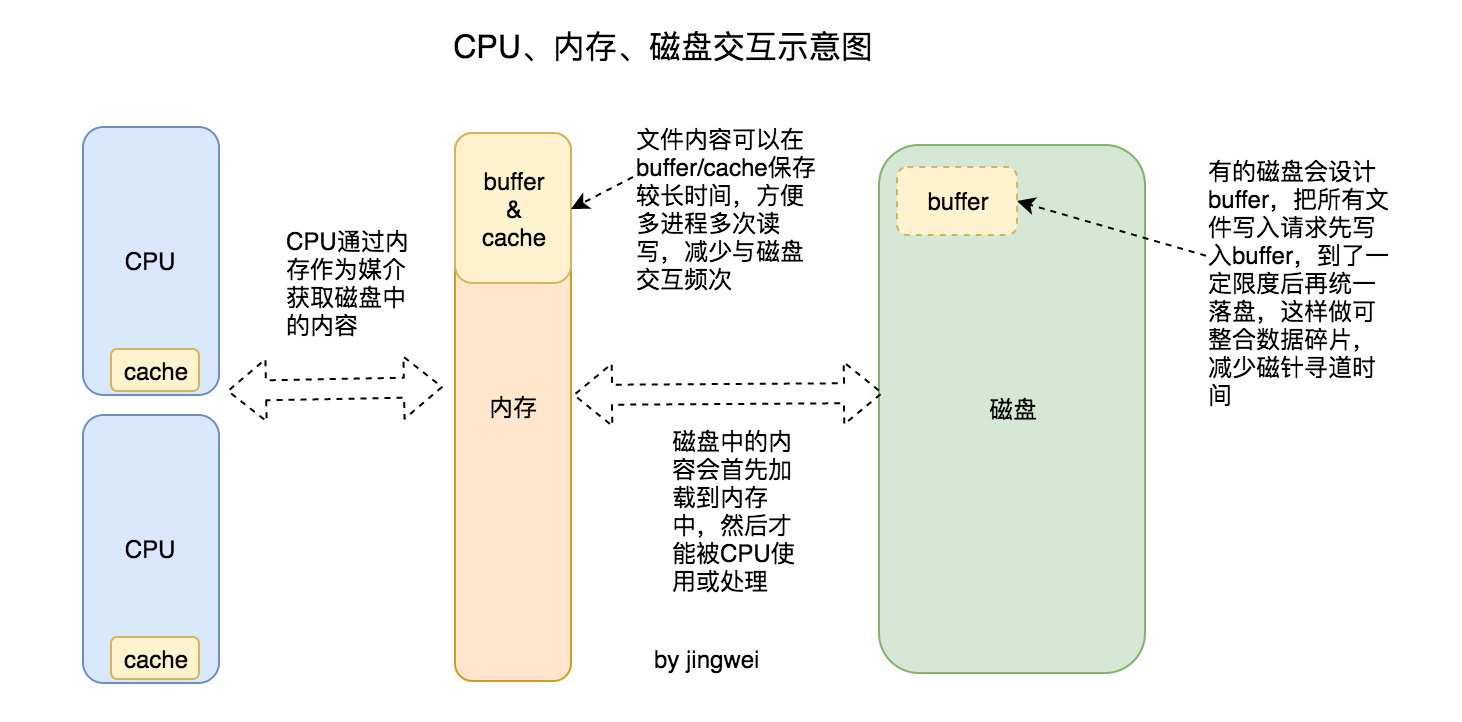
研究过 Linux 内核源码的开发者知道,Linux 文件系统有着非常复杂的运行机制(可参考《 深入理解LINUX内核(第三版)》文件系统相关的章节),为了能顺利完成此博文,我这里只画了一张简化版的示意图。其中① CPU通过内存作为媒介来获取磁盘(包括 SSD、HDD、Flash 等)中的内容;② 磁盘中的内容会首先加载到内存中,然后才能被 CPU 使用或处理;③ 普通文件可能会被加载到内存中的页高速缓存(buffer/cache),这样能够在内存中停留的时间久一些,方便多进程多次读写,从而减少与磁盘的交互频次。④ 值得说明的是,缓存并不适用所有的场景,比如数据库文件要实时落盘才有意义,实时落盘的应用场景下可以显式使用直接 I/O 传送 的模式来满足需求。
通过上面的分析可以知道,方案 B 中两次落盘的过程所花费的时间大概率不会多于一次落盘过程所花时间的两倍,因为:① 第二次落盘与第一次落盘之间没有阻塞,即第一次落盘与第二次落盘有望同时进行(要看当时内核的调度情况,参考《Linux系统调度原理浅析 》)。② 采用 Streaming 模式时,第二次落盘过程中的读操作大概率直接从内存中获取到日志的文件内容,此种情况的效率可谓非常高了。③ 内核有专门的线程处理内存中 buffer/cache 的落盘情况,因此两次落盘不会另外占用过多的 CPU 时间。
不过可以明显注意到 方案 B 相对于 方案 A 多了一个 Straming 进程,这显然会增加宿主机的负担。因此方案 A 是最佳的日志收集方案,只有在方案 A 无法实施(比如那些没有办法把日志写入 stdout/stderr 的应用)的时候才建议考虑方案 B。
Ext4文件系统——一个100M的文件是如何保存在磁盘上的
当前我所接触到的服务器的磁盘文件系统都是 Ext4 格式,那么 Ext4 存在性能瓶颈吗?有没有其他更好的文件系统选型呢?我浏览了一圈大家对 Ext4 的评价,确认了使用 Ext4 是最佳实践。不过好奇心驱使让我想进一步探究 Ext4 保存文件的方式:一个 100M 的文件是如何保存在磁盘上的?
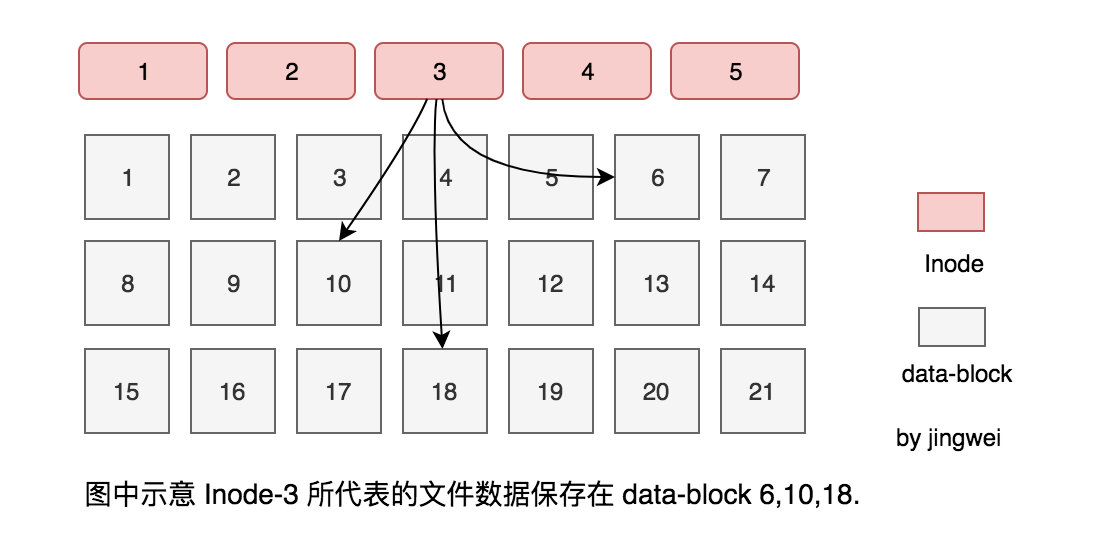
简单地讲(详细情况可阅读相关的参考文章),① 磁盘在初始化以后,磁盘上除了一些元数据还包含 data-block 和 Inode 这两种结构,其中 data-block 有固定大小(比如每个 4k),负责存放文件的内容体;Inode 则负责存放文件的元属性(比如归属、类型、权限、时间戳等)以及 data-block 的索引。② 当创建一个文件的时候,内核会参考 Inode bitmap(属于元数据之一)从空闲的 Inode 中获取一个 Inode 并与文件名进行绑定;③ 当向文件中添加数据时,内核会参考 Block bitmap(也属于元数据之一)从空闲的 data-block 中获取相应数量的 data-block 资源,然后把数据写到这些 data-block 中,最后更新 Inode 中 data-block 的索引值。
这里面有一些值得思考的点,比如:data-block 的分布情况会影响文件的读写效率吗?data-block 的分布是如何决定的?如何优化 data-block 的分布情况?这里我只回答第一个问题,data-block 的分布情况会影响文件的读写效率,而这也是磁盘的顺序读写和随机读写两个指标存在的意义;其他两个问题已经属于比较高阶的 Ext4 文件系统的知识,如果感兴趣可以自己深挖一下,本文就不展开了,大家只需知道 Ext4 对 data-block 的分布做了很多优化方案。
磁盘寻址(主要指机械磁盘)
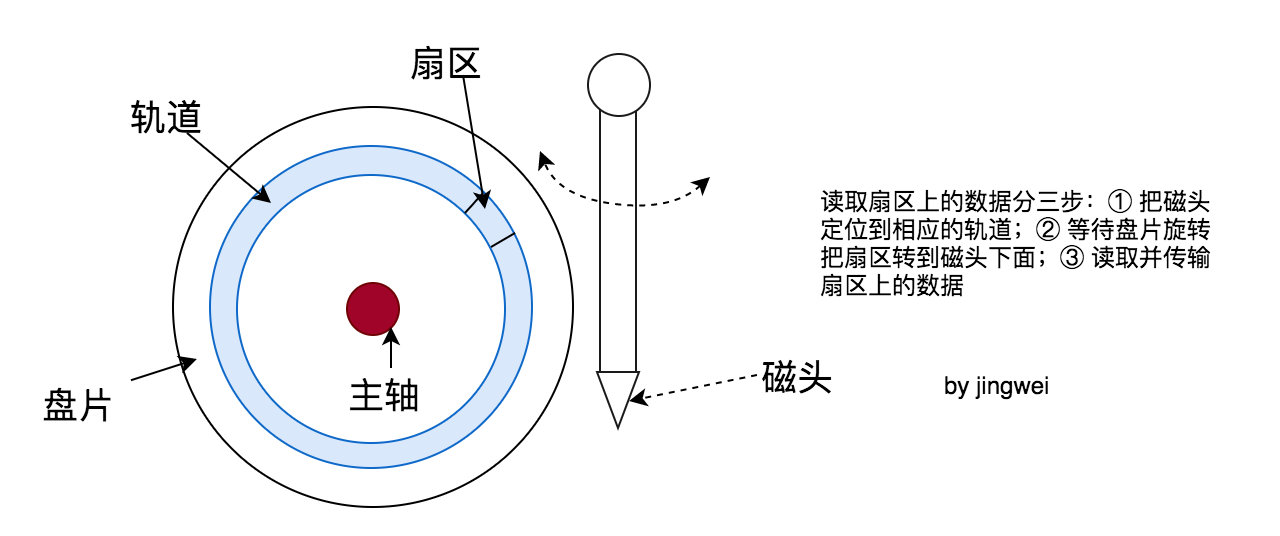
上一小节提到 data-block 的分布情况会影响文件的读写效率。那么为什么会这样呢?我以机械硬盘(HDD)为例(SSD 通过电路实现寻址,机制不一样),如上图所示,文件数据分布在磁盘的某条轨道的某个扇区里。可以简单把磁头读取特定扇区上的数据的过程分成三步:① 把磁头定位到相应的轨道;② 等待盘片旋转使扇区正对磁头下方;③ 磁头读取并传输扇区的数据。上面三步中每个步骤都需要耗时,而由于前两步涉及到了机械运动,因此耗时比第三步的耗时多。
我们以读取一个文件为例,并假设文件数据分散在 3 个扇区中,那么可以对应到下面的三个场景:a)三个扇区分布在不同的轨道的不同扇区,这种情况下读每个扇区的数据都需要经历 “定位轨道”、“扇区正对磁头”、“读取数据”三步;b)三个扇区分布在同一个轨道上,但扇区随机分布,这种情况下除了读第一个扇区的数据时要经历上面提到的三个步骤,读后面两个扇区的数据时只需要“扇区正对磁头”、“读取数据”这两步就可以完成;c)三个扇区分布在同一个轨道上且连续,这种情况下除了读第一个扇区的数据要经历上面提到的三个步骤,读后面两个扇区的数据只需要“读取数据”这一步就可以了。对于上面提到的三个场景,很明显场景 c 的理论耗时将是最短的,这也是 data-block 的最优分布方式。
对于磁盘寻址,业界把磁盘每秒钟能够实现的寻址动作(包含以上三种场景)定义为 IOPS(Input/Output Operations Per Second),并用它作为权衡磁盘性能的一个指标;通过上面的讨论可以知道,磁盘指标中随机读写的 IOPS 和按顺序读写的 IOPS 是不同的,理论上后者的数值要大于前者。如果商家比较黑,可能只给出顺序读写的 IOPS,数据看起来比较漂亮;如果商家比较良心,可能会给出两个参考值,分别对应随机读写的 IOPS 和 顺序读写的 IOPS。
顺便提一下,对于机械硬盘来说,随机 IOPS 一般分布在 100-200 区间,也就是说机械硬盘每秒钟可以实现 100-200 次的随机寻址动作。
SSD的IOPS指标优于HDD
SSD 属于 Flash 的一种,通过逻辑电路实现 data-block 的寻址;而电路的速度肯定优于机械运动,因此 SSD 随机读写的 IOPS 指标比 HDD 的 IOPS 要高很多。我看几篇博客里给的数据,SSD 的 随机读写 IOPS 随随便便就可以飙到 10k (具体的也要看 SSD 的质量而定),从这个角度来看能用 SSD 的话就不要使用 HDD 了,真的会提速!当然 SSD 也有一些缺点,比如贵,一般 SSD 的价钱是 HDD 价钱的三倍;除了贵之外, 这篇博客 还报告说 SSD 的最大响应时间浮动比较大(差的情况要到几十毫秒,当然也和 SSD 的质量相关),遇到这种情况时读写文件就会显得卡顿了,或许会让进程陷入 D 状态(参考《Linux的CPU-Load虚高之进程的D状态》。
现在已经了解了 SSD 和 HDD 之间的差别了,可以根据具体情况对磁盘进行选型了。对于本文前面提到的日志收集方案来说,Empty-Dir 与 log-file.log 直接与业务进程绑定,而同一台宿主机上面可能同时运行几十甚至上百个业务进程,因此这部分选用 SSD 作为存储媒介最合适。对于日志最终的归宿 Logging-Backend 来说,则完全可以基于 HDD 作为存储媒介做高可用方案。
小结
本文从 Kubernetes 日志收集的方案开始,对文件系统、Ext4、磁盘寻址、SSD/HDD 等概念进行了探索,为优化日志收集方案提供了参考。
于我而言,其实是通过 Kubernetes 日志收集这件事情把很久以前学习的知识点串接起来,从而达到学以致用的目的。最后,希望本文能给大家一些启发和帮助。
参考
- Logging Architecture - Kubernetes K8s 官方给出的日志收集方案列表,几乎涵盖了所有的场景
- 从 Clean-Architecture 谈架构原理及其应用 - 敬维 之前写的架构相关的文章
- 深入理解LINUX内核(第三版) (豆瓣) 压箱底的书,讲的太细,不建议读,但可作为参考书
- Linux系统调度原理浅析 - 敬维 之前写的 Linux 调度器相关的博客
- Linux 查看内存(free buffer cache) - 赵磊的技术博客 - ITeye博客 可以解答 buff/cache 是什么
- Linux 的 EXT4 文件系统的历史、特性以及最佳实践 内容很全面,比如 EXT4 中可以减少碎片的特性
- Ext4文件系统架构分析(一) - AlanTu - 博客园
- linux中inode的工作原理-I’m Groot-51CTO博客
- 硬盘分区、寻址和系统启动过程 - 黄刚的专栏 - CSDN博客
- 磁盘性能指标—IOPS、吞吐量及测试-秋天的童话-51CTO博客 介绍硬盘相关参数(IOPS)及测试数据的文章,很详细,强烈推荐
- IOPS_百度百科 介绍 IOPS,给出了各种磁盘的参考指标数据
- Linux的CPU-Load虚高之进程的D状态 - 敬维 进程的 D 状态的表现,之前写的一篇博文
- SSD硬盘和HDD硬盘的对比_百度经验 对比 SSD 以及 HDD
